2008. 11. 14. 13:13ㆍStudying Statistics/AMOS
AMOS란 Analysis of MOment Structures의 약자로 LISREL(LInear Structural RELations), EQS(EQuationS) 등과 함께 구조방정식모형 분석에 자주 사용되는 통계 소프트웨어이다. AMOS는 Temple University의 James L. Arbuckle 교수에 의해 처음 개발되었으며, 현재는 ver. 7.0까지 출시되었다.
구조방정식모델 분석을 위한 프로그램으로 가장 처음 개발되었고 가장 많이 쓰이고 있는 LISREL의 경우, 분석을 위해 사용자가 직접 모형을 프로그래밍해야 한다는 단점이 있는 반면, AMOS는 GUI를 따르고 있어 그래픽 요소들을 배치함으로써 모형을 프로그래밍할 수 있어 분석을 보다 용이하게 할 수 있다는 장점을 가지고 있다. LISREL은 도스용, AMOS는 윈도우용이라고 생각하면 쉽게 이해할 수 있겠다.
본인도 이제 처음으로 AMOS 공부를 시작하는 입문자이다. 여러 AMOS 관련 사이트를 돌아다니다가 AMOS의 개요를 알기쉽게 소개한 글을 보게 되어 소개하고자 한다.
아래 내용은 mySTATISTICS.net (http://www.mystatistic.net)이라는 사이트에 올려져 있는 글이다.
구조방정식 이해하기 (사례분석)
1
지금까지 우리는 독립변수 (Independent variable) 과 종속변수 (Dependent variable) 에 익숙합니다. 하지만 구조방정식 모델에선 독립변수와 종속변수라는 개념대신 관측변수(observed variable) 와 잠재변수 (latent variable) 그리고 외생변수 (exogenous variable) 와 내생변수 (endogenous variable)의 개념으로 변수들이 나타내어집니다.
관측변수들이 (설문지에 해당하는 항목들) 모여서 하나의 잠재변수를 형성하게 되고 이러한 잠재변수들끼리 외생변수와 내생변수의 개념을 가지고 모델을 형성하게 됩니다. 외생변수는 모델 내에서 한번도 다른 변수의 결과가 되지 않는 변수이며, 내생변수란 최소 한번은 모델 내에서 결과가 되어지는 모델입니다. 약간은 생소하지만 우리가 사례들을 이해하기 위해선 꼭 알아야 될 사항입니다(참고로 관측변수는 정사각형이나 직사각형이 사용되며 잠재변수는 원으로써 나타내어 집니다).
그럼 우선 간단히 이러한 내용들이 어떻게 사용되는지 알아보도록 하겠습니다. 예를 들어서 외제 자동차에 대한 이미지 (Car image) 조사를 할 경우 다음과 같은 항목들을 만들었습니다.
만약에 설문지 내용이
1) 외제차 BMW에 대한 디자인 (Design)은 어떻다고 생각되십니까?
2) 외제차 BMW에 대한 엔진의 기능 (Engine) 어떻다고 생각되십니까?
3) 외제차 BMW에 대한 가격은 (Price) 어떻다고 생각되십니까?
* 1번 매우 만족한다, 2번 만족한다, 3번 그저 그렇다 4 불만족스럽다, 5번 매우 불만족스럽다
라고 할 때 여기서 항목 1, 2, 3 이 관측변수가 되고, 이 세 가지 항목으로 구성되는 자동차에 대한 이미지가 바로 잠재 변수가 되는 것입니다. 그래서 아래와 같은 모델로써 만들어지는 것입니다.
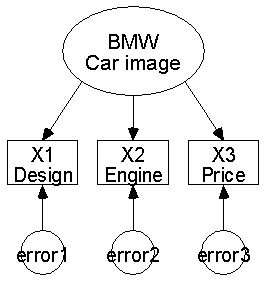
아주 쉽죠? 그럼 모델을 하나 더 만들어 볼까요?
두 번째 예는 소비자의 자동차 소비 구매성향 (Purchase intention)에 대해서 만들어 보겠습니다. 우선 자동차 구매성향에 대한 4가지의 항목을 있다고 가정해 보겠습니다.
1) 나는 차에 외제차에 대해 관심 (Interest) 이 많다
2) 나는 새 차로 교체할 시 멋지고 비싼 차 (Luxury)로 구입 할 것이다.
3) 나는 사회적 지위 (Position) 에 맞는 차를 타야된다고 생각한다.
4) 나는 안전한 차 (Safety)를 타고싶다.
* 1번 매우 만족한다, 2번 만족한다, 3번 그저 그렇다 4 불만족스럽다, 5번 매우 불만족스럽다
라고 한다면 역시 항목 1,2,3,4 는 관측변수가 되고 소비 구매성향은 잠재변수가 되는 것입니다. 그래서 이것을 모델로 표시하면 다음과 같이 되겠죠?
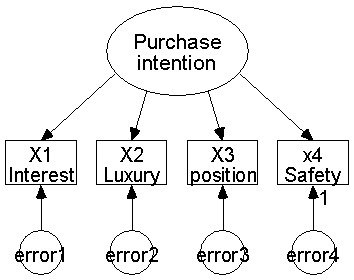
그렇다면 이 두 모델을 연결시킬 수 있겠죠?
그럼 이 두 모델을 연결하면 다음과 같이 될 것입니다. 그래서 외제차에 대한 이미지가 어떻게 자동차 구매성향에 영향을 미치는가에 대한 모델을 간단하게 만들어 봤습니다.
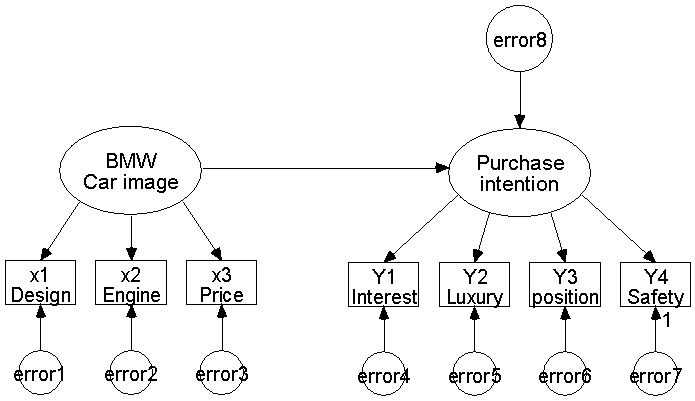
이 경우 앞에서 독립변수 역할을 하는 차 이미지가 외생변수가 되는 것이고 종속변수의 역할을 하는 소비구매 경향이 내생변수가 되는 것 입니다. (두 번째 모델에서 X1, X2, X3, X4 가 Y1, Y2, Y3, Y4 로 바꿨는데 그것은 두 번째 모델이 종속변수로 되는 관계로 문자만 변한 거지 기본개념은 변한 게 없음을 알려 드립니다)
물론 여기 까지는 회귀분석 (Regression)으로도 가능합니다.
하지만 회귀분석의 경우 항목들에 대한 평균값을 내어 하나의 변수로 만들어주거나 각각의 항목들을 하나씩 연결 시켜야 하는 반면, 구조 방정식 모델의 경우 그럴 필요가 없으며 특히 이러한 잠재변수가 2개 이상일 경우 회귀분석의 경우 각 단계 단계마다 각각의 유의치를 계산해야 되지만 구조방정식 모델의 경우 잠재변수가 2개 이상이라 하더라도 변수간 유의치를 단 한번에 볼 수 있는 장점이 있습니다.
그럼 다음의 사례로 가볼까요?
2
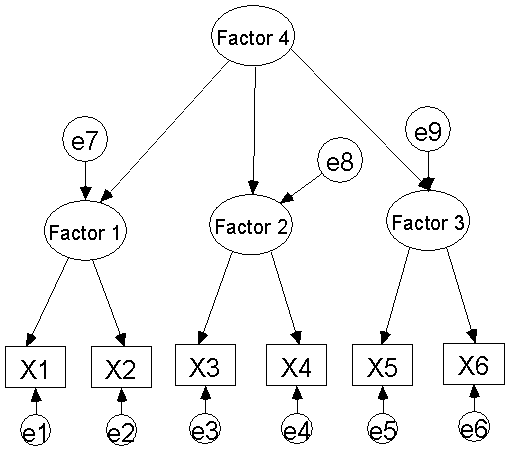
첫 번째 사례에서 언급한 것처럼, 우리는 9개의 관측 변수로 4개의 잠재변수를 만든 후 다시 4개의 잠재변수를 두 개의 독립변수와 두 개의 종속변수를 만들어 그 관계를 보도록 하겠습니다. 약간 복잡해 보이지만 자세히 보면 첫 번째 사례와 동일합니다.
직장에서 직업 만족도를 측정하기 위한 모델개발을 위해 우선 외생변수로는 직장에서 수입에 대한 만족도 (Income Satisfaction) 와 직장내 작업환경 (Work Environment)로 지정하였고, 내생변수로는 직업 만족도 (Job Satisfaction) 와 직장내 협동심 (Cooperation)로 하였습니다.
수입만족도 측정을 위해 두 개의 아이템 (X1, X2) 을 이용하였고, 작업환경을 측정하기 위해 세 개 의 아이템 (X3, X4, X5 )을 이용하였습니다. 직업 만족도 역시 세 개의 아이템 (Y1, Y2, Y3)을 이용하였고, 직장내 협동심을 세 개의 아이템 (Y4, Y5, Y6)을 사용 하였습니다. 이 경우 아래의 그림과 같은 모델을 만들 수 있습니다.
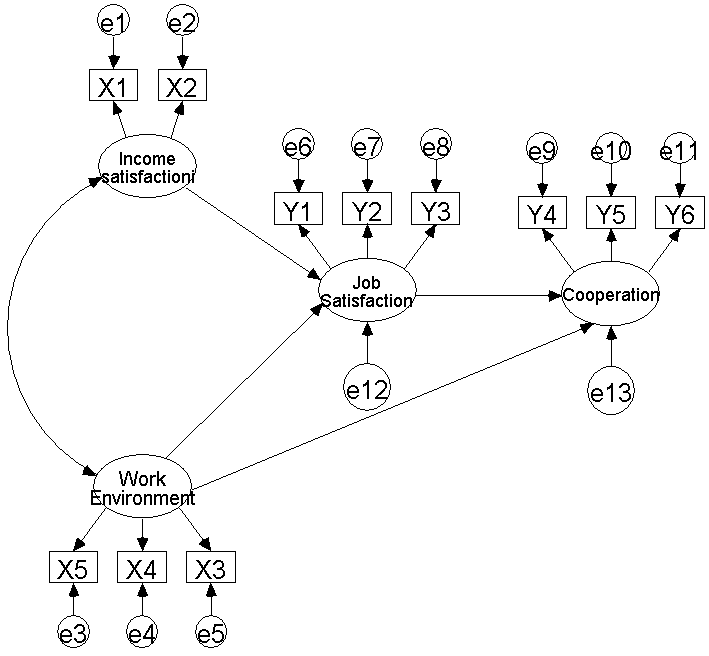
이러한 경우 X1, X2, X3, X4, X5 들은 역시 관측변수들로써 잠재변수 (수입 만족도, 작업환경)를 구성하는 아이템이 되는 것이며, Y1, Y2, Y3, Y4, Y5, Y6 역시 잠재변수 (직업 만족도, 직장내 협동심)를 구성하는 관측변수가 되는 것입니다.
자, 그러면 이 모델을 한번 볼까요?
우선 수입에 대한 만족도가 직업 만족도에 대한 영향을 미치고 직장환경 역시 직업 만족도에 영향을 미칩니다.
그리고 직장환경은 다시 직장내 협동심에 영향을 미치며 직업 만족도 역시 직장내 협동심에 영향을 미치는 것으로 나타났습니다.
이럴 경우 회귀분석은 각각의 변수들 간의 유의치를 보지 못합니다. 예를 들어서 수입만족도에서 직업 만족도 까지만 유의치를 볼 수 있고 그다음 직업만족에서 다시 협동심으로 가는 경로의 유의치 밖에 보여주지 못합니다. 하지만 구조방정식모델에서는 그 모든 경로의 유의치 들을 한꺼번에 보여준답니다.
특히 작업환경에서 협동심 (Work environment -> Cooperation)으로 가는 직접적 경로와 작업환경에서 직업 만족도를 통한 협동심 (Work environment -> Job Satisfaction -> Cooperation)으로 가는 간접적 효과 등을 비교할 수 있는 장점 또한 있습니다.
지금까지 전혀 어렵지 않으시죠? 그럼 다음으로 넘어가 볼까요?
3
이번엔 경로분석 (Path analysis) 에 대해서 알아보도록 하겠습니다.
일단 경로 분석은 축자 모델 (recursive model)과 비축자 모델(non-recursive model)로 나뉘질 수 있습니다. 축자 모델은 변수 간에 쌍방향 인과관계 (reciprocal causation) 나 순환적 인과관계 (feedback loops) 가 없는 것이고 비축자 모델은 이러한 것들이 있는 것입니다.
무슨 소린지 잘 모르시겠다구요? 일단 그림을 보세요. 첫 번째 그림은 축자 모델입니다. 모든 화살표 (경로) 들이 오로지 한 방향으로만 움직이고 있습니다 (왼쪽에서 오른쪽으로). 즉 순환적 인과관계나 쌍방향 인과관계가 없는 모델이 바로 축자 모델이라 할 수 있습니다.
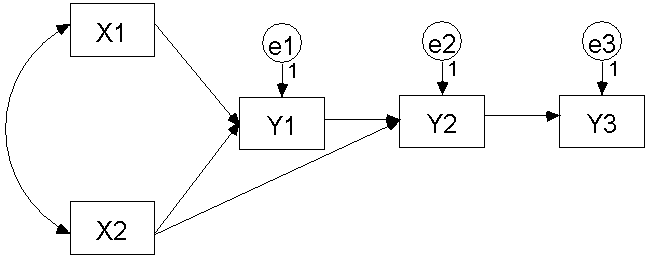
그 다음은 비축자 모델입니다. 축자 모델과 다른 점은 화살표들이 서로 주고받는 것이 다른 점입니다. 다시 말해서 순환적 인과관계나 쌍방향 인과관계가 있는 모델이라고 할 수 있습니다. 이런 모델을 우리는 비축자 모델 이라고 합니다.
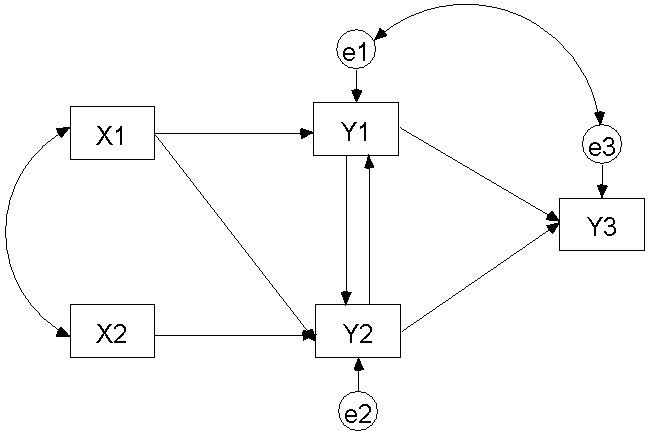
4
다음은 요인분석에 대한 설명입니다.
요인분석은 크게 두 가지로 분류 될 수 있습니다. 첫째는 탐색적 요인분석 방법으로써 주로 SPSS 등에서 쓰여지는 방법입니다. 그리고 나머지 한 가지는 구조방정식 모델에서 쓰여지는 확인적 요인분석 방법이 되겠습니다.
첫째로 탐색적 요인분석의 경우 수많은 항목들을 비슷한 항목들로 줄이기 위한 방법으로 주로 Varimax 기법을 통한 Eigen value를 기준으로 묶여 집니다. 항목의 숫자를 줄이고 분석의 효율성을 높이기 위해 쓰여지는 방법이라고 말씀드릴 수 있습니다. 하지만 중요한 점은 이 방법은 요인분석을 하기 전에 어떠한 항목들이 서로 묶인다고 단정할 수 없다는 점입니다. 다시 말하면 수리적 분석에 의해 (각 성분들이 1개 이상의 요인들로 묶여지게 됨) 요인들이 결정이 됩니다.
(1) 탐색적 요인분석 (Exploratory factor analysis, 주로 SPSS에서 쓰이는 방법이죠)
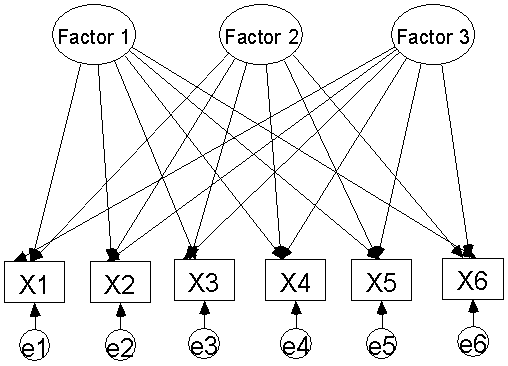
이에 반해 확인적 요인분석 방법은 탐색적 요인분석과는 전혀 다른 분석방법이 사용됩니다. 우선 탐색적 분석방법처럼 요인들을 서로 수치적 결과에 따라 묶는 것이 아니라, 이론적 배경에 의해서 잠재변수를 구성하는 관측변수들이 이미 지정되어 있다는 점입니다. 이점이 탐색적 요인분석과 가장 다른 점이라고 할 수 있습니다. 다시 말해서 항목들이 탐색적 요인분석에 상관없이, 이미 잠재변수를 구성하는 관측변수들이 이론적 배경에 의해 정해져 있고 그 상황 하에서 모델이 만들어지면 분석되는 방법이라고 할 수 있습니다.
(2) 확인적 요인분석 (Confirmatory factor analysis, 주로 SEM에서 쓰이는 방법이죠)
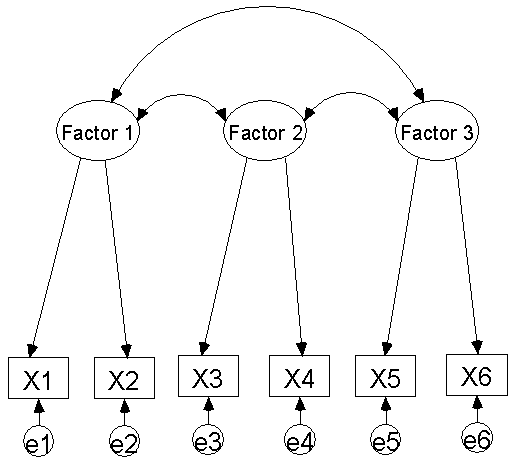
(3) 고차 요인분석 (Higher-order factor analysis)
이 경우는 확인적 요인분석이 두 번째 됐다고(두번 실시되었다고) 보면 이해하기 쉬운 경우입니다.
5
이번에는 Reflective model 과 Formative model에서 알아보도록 하겠습니다.
일단 Reflective model은 Factor view of Multidimensional constructs 로 불리기도 하며, Formative model은 Composite view of Multidimensional Constructs 라고도 불립니다.
일단 두 모델의 모형은 다음과 같습니다.
(1) Reflective model
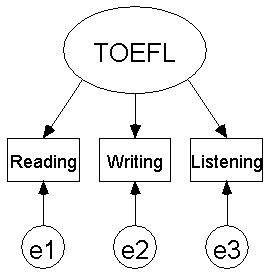
처음모델은 우리가 지금까지 얘기했던 모델이라고 할 수 있습니다.
(2) Formative model
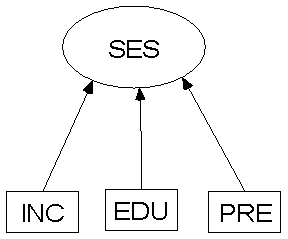
그런데 두 번째 모델은 뭔가가 좀 다르죠? 맞습니다. 화살표가 첫 번째 모델과 반대로 되어 있음을 알 수 있습니다. 바로 처음 모델은 우리가 지금까지 사용한 Reflective model 이고, 두 번째 모델이 바로 Formative model 입니다. 그럼 저 모델이 어떻게 다른지 알아볼까요? 언뜻 보기엔 아주 비슷하게 보이지만 큰 차이가 있습니다.
첫 번째 모델의 경우 그림에서 나타난 것처럼 밑에 세 개의 관측변수가 위의 잠재변수를 형성합니다. 예를 들어서 TOEFL 시험점수의 경우 이를 측정하는데 읽기(Reading), 쓰기 (Writing), 듣기 (Listening)로 구성되어 있으므로 TOEEL은 3가지 관측변수의 잠재변수가 되는 것이죠. 이 세 가지 변수들이 TOEFL 점수의 관측변수가 되며 서로 긴밀하게 연관되어 있을 뿐만 아니라 TOEFL은이 세 가지 변수들로써 구성되어 있다는 것을 뜻합니다.
그럼 두 번째 모델을 볼까요? 위에 보인 두 번째 모델은 유명한 Socio-economic status (SES) 모델입니다. 여기선 사람의 사회경제적 지위 (SES) 를 수입수준 (income level, INC), 직업적 명성 (occupational prestige, PRE), 그리고 교육수준 (education, EUD)으로 나누었습니다.
이 모델에서는 보시다시피 밑에 있는 세 개의 요인들이 사람의 사회경제적 지위를 형성하고 있는 모습을 보여줍니다. 다시 말해서 세 가지 요인이 모두 사회적 지위에 영향을 미친다고 보는 겁니다. 위의 것(토플점수 모델)은 위의 잠재변수가 밑에 있는 관측변수에 영향을 미치지만, 두 번째 모델(SES 모델)은 밑의 요인들이 위의 변수에 영향을 미치는 겁니다.
그리고 또 하나 다른 점은 변수들 간의 상관관계입니다. 앞서 말했듯이 읽기, 쓰기, 듣기는 서로 강하게 연관 되어 있지만, 두 번째 경우 수입수준과 직업적 명성 그리고 교육수준은 어느 정도 상관은 있지만 서로 강하게 연관돼 있지 않습니다. 수입이 높다고 그 사람의 교육수준이 높은 것은 아니고 직업이 사회적으로 존경받는 자리라고 하더라도 수입이 많은 건 아닌 것과 비슷한 이치입니다.
또 다른 하나는 에러변수인데 일단 Reflective 의 경우 측정에러 (measurement) 가 있으나 Formative 경우 에러가 존재하지 않습니다. 왜냐하면 변수에 영향을 미치는 변수들이 외생변수이기 때문입니다. 이 두 모델간의 에러변수에 대해선 상당히 복잡한 설명이 필요하므로 여기선 생략하도록 하겠습니다.
사실 학계에서도 이 두 가지 모델에 대해서 여러 가지 연구결과와 학설이 나오고 있지만 (SES 모델도 reflective model로 보시는 분들도 계십니다), 일단 이런 정도로만 아셔도 여러분이 두 모델의 개념을 잡으시는데 충분히 도움이 됐으리라 생각합니다.
6
이번에는 두 그룹 이상의 모델에서 어떻게 구조방정식 모델을 사용하는지 알아보겠습니다.
개인적으로 Multiple group analysis 야말로 구조방정식의 백미라고 말씀드리고 싶습니다. 그 이유는 이 구조방정식 모델 안에 필요한 많은 분석방법들이 사용되기 때문입니다. 주로 남자나 여자 그룹, 어떠한 분류에 따른 높은 집단 혹은 낮은 집단, 그리고 국가별 인종별 등의 그룹으로 나누어서 한 모델 안에 그룹간의 차이가 없는지 있는지, 있다면 어느 점에서 차이가 나는지 등을 알 수 있습니다.
제가 이 분석 방법 전에 반드시 알려드리고 싶은 점은 절대로 그룹 분석 시 두 그룹을 따로따로 돌려서 경로간의 크기를 비교하지 말라는 점입니다 (예로 베타나 감마값 비교). 이건 논리적으로 따지자면 다른 두 수학 시험지를 다른 두 반 학생들에게 보게 한 후 한 반이 다른 반 학생들과 비교해서 시험을 '잘 봤다' 혹은 '못 봤다' 하는 이치입니다. 다시 말해서 논리적으로 말이 전혀 안 되는 경우죠. 우리가 두 집단을 비교하기 위해선 우선 시험지가 같은지 그것을 확인하는 작업이 필요한 겁니다. 이게 그룹분석의 가장 중요한 점입니다. 그리고 많은 논문에서 무시되어져 왔던 부분이기도 하구요.
예를 들어서 아래와 같은 두 집단에서 모델을 비교한다고 가정해 보겠습니다.
우선 우리가 사례분석 2에서 보여준 모델을 기본으로 하죠. 일단 기본모델을 바탕으로 한국과 일본 직장인을 비교를 한다고 가정해 보도록 하겠습니다.
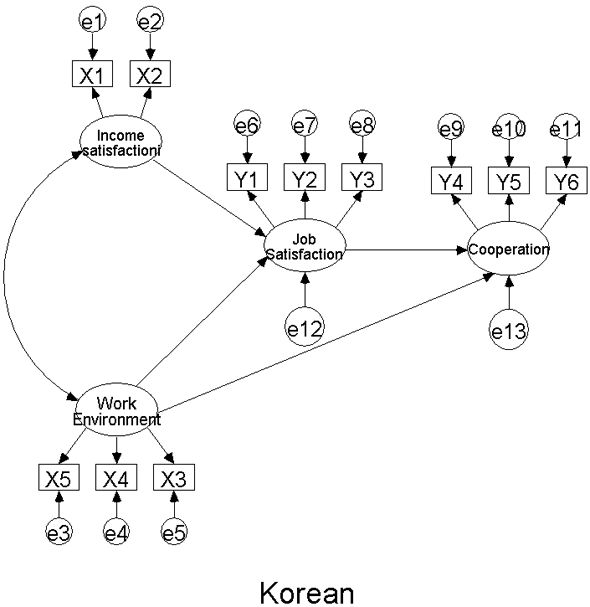
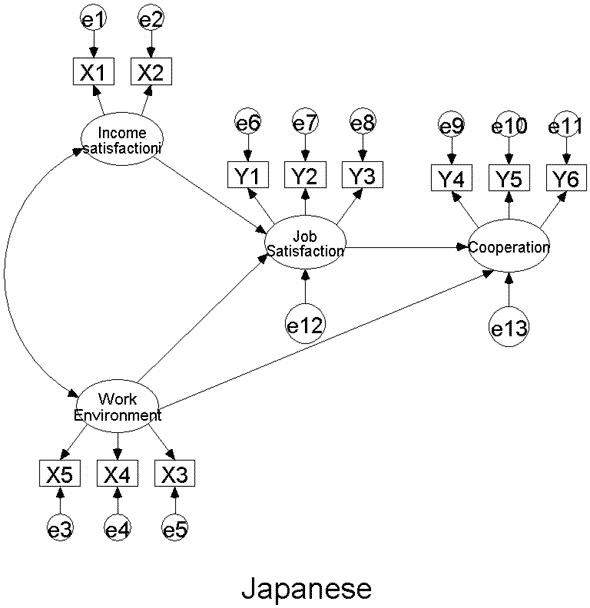
우선 이 분석방법을 이용하기 위해서 위와 같은 두 개의 그룹을 만듭니다. 물론 모델 자체는 같지만 한국 직장인과 일본 직장인에 관한 데이터는 각기 다르므로 같은 모델을 기본으로 두 개의 그룹을 만듭니다.
그 후에 하는 절차가 두 그룹 간 확인적 요인분석 하는 것입니다. 그래서 두 그룹 간 관측변수와 잠재변수 사이의 람다값이 좋고 두 그룹을 제약했을 경우 유의한 차이가 나지 않으면 (카이 스퀘어를 통한 방법을 통해) 다음 단계인 모델 비교로 넘어 가는 것입니다.
이 과정이 다시 말해서 두 시험지가 두 반 학생에게 똑같은 다른지 판별하는 방법이라고 할 수 있겠습니다. 만약 제약 모델과 원래 모델이 다르다면 다음 단계로 넘어간다 하더라도 모델 분석에 의미가 없습니다. 왜냐하면 이미 두 그룹 간 설문지 자체가 동등하지 못하다고 여겨지기 때문입니다.
그 다음은 만약 두 모델에서 확인적 요인분석을 마쳤다면 두 모델 간 경로들 간에 차이가 있는지 없는지를 확인하는 차례입니다. 여기선 물론 여러 가지 방법이 있습니다. EQS 프로그램의 경우 LM test를 통하여 결과를 알 수 있고, Lisrel 이나 AMOS 의 경우 각각의 경로들을 서로 제약해서 결과를 찾아내는 방법이 있습니다.
위에 방법은 사실 머리가 아플 정도로 복잡하기 때문에 일단 여기선 간단한 개념만 설명 드렸습니다. 물론 아주 자세한 방법을 아는 것이 중요하지만, 위에서 간단히 말씀드린 것처럼 그룹 분석의 개념만 일단 알아두셔도 상당한 도움이 되시리라 믿습니다.
7
이 장에선 그룹 간 constraint model (제약 모델) 에 대해 잠깐 설명하고자 합니다.
사례분석 6에 나왔던 상황일 경우 이 경우가 사용됩니다. 기본적인 개념은 두 그룹 간 혹은 한 모델 내에서 경로들을 서로 같다고 정해주는 방법으로 경로 간 크기나 그룹 간 경로들 간의 차이를 보는 방법이라고 말씀드릴 수 있겠습니다.
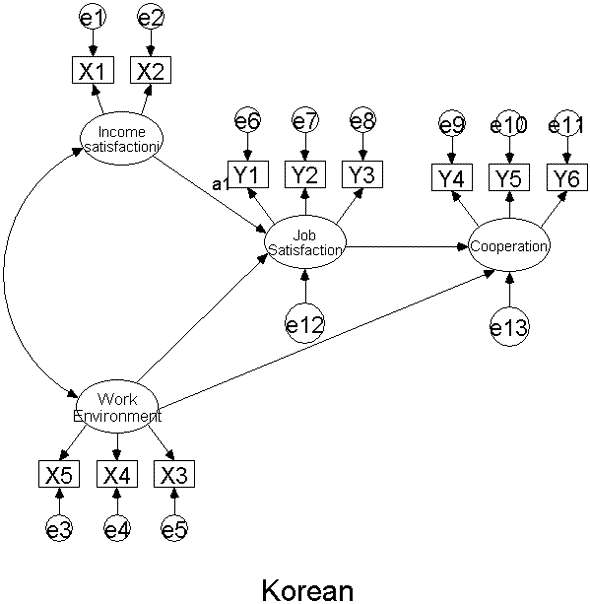
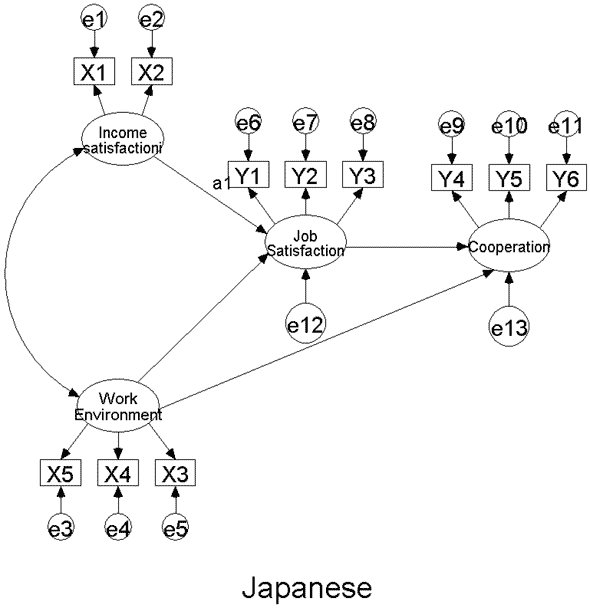
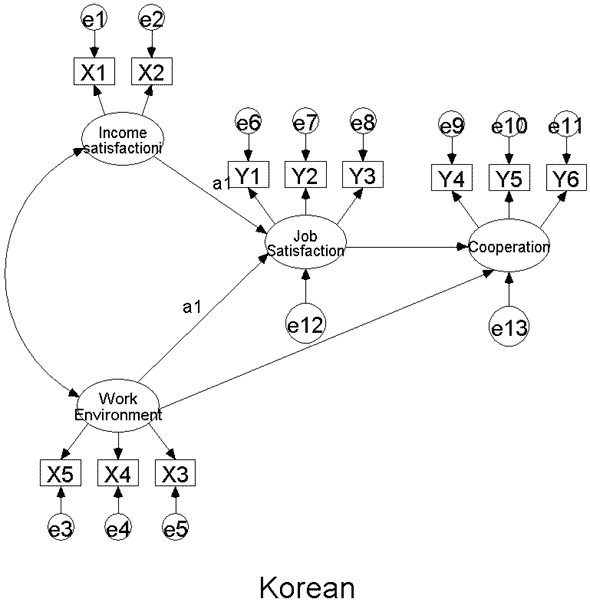
우선 첫 번째 모델과 두 번째 모델은 그룹 분석의 경우에 수입 만족도 (Income satisfaction) 와 직장 만족도 (Job satisfaction) 로 가는 경로를 한국 직장인 그룹과 일본 직장인 그룹 간에 똑같이 제약을 해준 경우입니다.
이런 제약을 한 후 카이스퀘어 값으로 유의한 차이를 검증합니다. 그리고 마지막 세 번째 모델의 경우 한 모델 안에서 Income satisfaction -> Job satisfaction으로 가는 경로와 Work environment -> Job satisfaction으로 가는 경로들을 제약해 주는 경우입니다.
이와 같은 제약모델을 통해서 우리는 경로 간에 유의한 차이가 있는지 없는지를 알 수 있게 되는 겁니다.
8
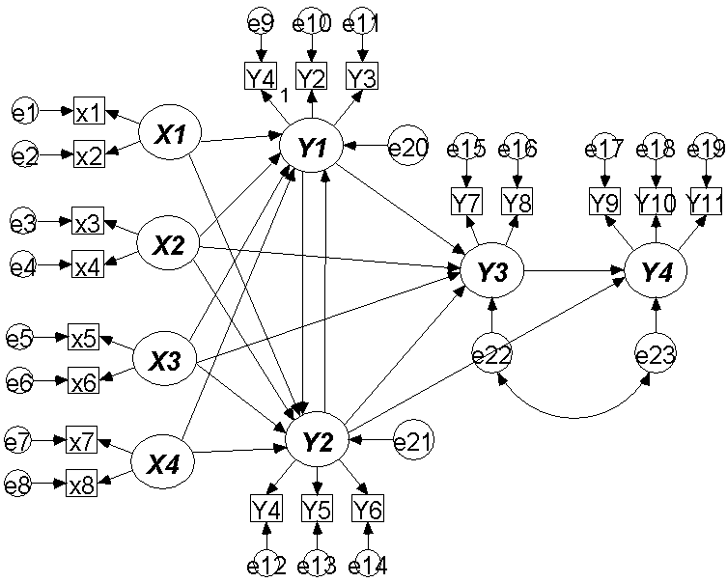
마지막으로 SEM의 전반적인 모델을 보여드리겠습니다.
저희 웹사이트에 있는 구조방정식 모델 예제에서 실제 해외 논문에서 발표된 모델들을 찾아보세요. 실제 여러분께서 읽은 내용의 모델들이 나온답니다.
'Studying Statistics > AMOS' 카테고리의 다른 글
| Amos에서 Heywood case의 처리 방법 (0) | 2008.12.13 |
|---|---|
| Amos에서 단일항목 값의 사용 (1) | 2008.12.13 |
| Amos 매뉴얼: Amos User's Guide (0) | 2008.11.03 |
| Amos Visual Basic의 기초적인 명령문 작성해보기 (0) | 2008.10.05 |
| AMOS 무작정 따라해 보기 (0) | 2008.10.04 |